
はじめに
みなさんこんにちは!本日は、昨今機能が追加され話題になったChat gptのコードインタープリターを使って簡単なデータ分析を行いたいと思います!
今回分析する対象は、プロ野球個人打撃成績です。
下記NPBのHPにある個人打撃成績から、2013年から2022年までの10年間で、成績が良い上位20選手に絞り、成績の傾向について分析しました。
https://npb.jp/bis/2023/stats/bat_c.html
※分析元となる資料を整備するのに大変な手間がかかるため20選手になりました。。。。
ここで調べたいことは、昨今パ高セ低と言われていますが、本当にパリーグの方がセリーグよりも成績がいいのか?という点を打撃の部分でまずは見ていきたいと思います。
(あくまで素人の分析になります。ご了承ください。)
分析結果(セリーグ)
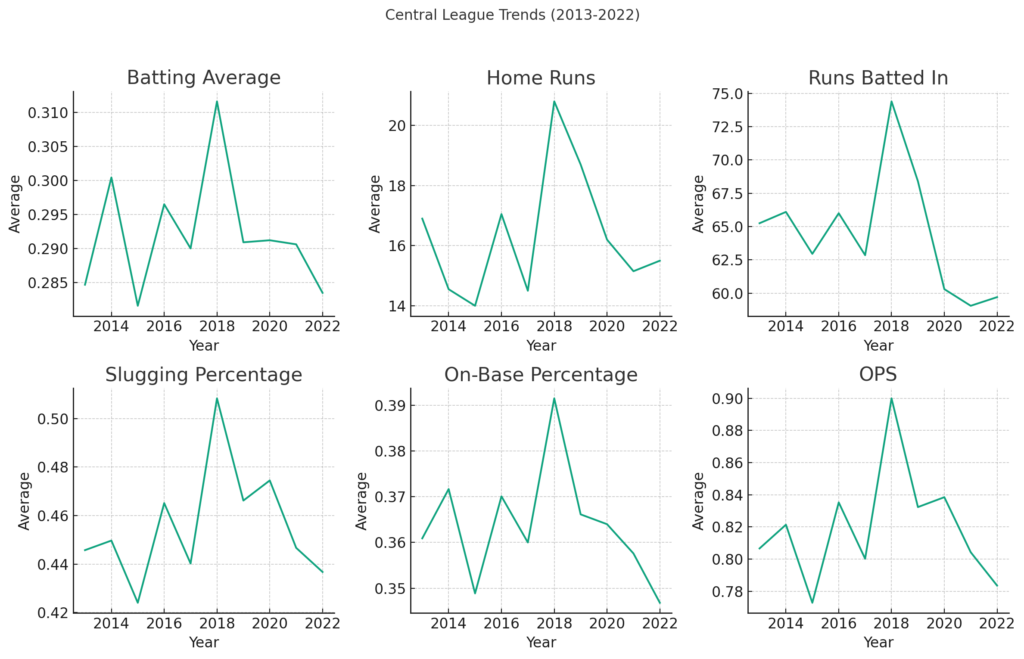
まずはセリーグの結果からお見せします。
以下がセリーグの上位20選手の平均打撃成績の傾向です。
※ 補足
打率(Batting Average)
本塁打(Home Runs)
打点(Runs Batted In)
長打率(Slugging Percentage)
出塁率(On-Base Percentage)
OPS(On Plus Slugging)→出塁率+長打率
セントラルリーグ
| 年度 | 打率 | 本塁打 | 打点 | 長打率 | 出塁率 | OPS |
|---|---|---|---|---|---|---|
| 2013 | 0.28465 | 16.90 | 65.25 | 0.44575 | 0.36090 | 0.80665 |
| 2014 | 0.30045 | 14.55 | 66.10 | 0.44970 | 0.37170 | 0.82140 |
| 2015 | 0.28155 | 14.00 | 62.95 | 0.42405 | 0.34885 | 0.77290 |
| 2016 | 0.29650 | 17.05 | 66.00 | 0.46515 | 0.37010 | 0.83525 |
| 2017 | 0.29000 | 14.50 | 62.85 | 0.44025 | 0.36000 | 0.80025 |
| 2018 | 0.31165 | 20.80 | 74.40 | 0.50835 | 0.39155 | 0.89990 |
| 2019 | 0.29090 | 18.70 | 68.40 | 0.46620 | 0.36615 | 0.83235 |
| 2020 | 0.29120 | 16.20 | 60.30 | 0.47450 | 0.36400 | 0.83850 |
| 2021 | 0.29060 | 15.15 | 59.05 | 0.44670 | 0.35760 | 0.80430 |
| 2022 | 0.28345 | 15.50 | 59.70 | 0.43675 | 0.34680 | 0.78355 |
ざっくり外観したところ、まず2018年に打者成績が非常に高くなっている部分が気になります。
この年は打率だけ見ると中日のビシエド選手が.348、巨人の坂本選手が.345など飛び抜けて成績がいい選手が全体的な成績を引っ張っていることが要因として考えられます。
しかし、他の打撃成績も2018年だけ飛び抜けて高いことから、例えばボールが飛びやすいものになっていた?といった推測もできるかも知れません。
それ以外の年は成績の上下はあるものの大体同じようなレンジにあることが見受けられます。
分析結果(パリーグ)
続いてパリーグの上位20選手の平均打撃成績の傾向です。

パシフィックリーグ
| 年度 | 打率 | 本塁打 | 打点 | 長打率 | 出塁率 | OPS |
|---|---|---|---|---|---|---|
| 2013 | 0.30065 | 15.30 | 70.80 | 0.45045 | 0.37030 | 0.82075 |
| 2014 | 0.29085 | 12.55 | 62.25 | 0.42795 | 0.36065 | 0.78860 |
| 2015 | 0.29010 | 14.95 | 66.80 | 0.43925 | 0.37005 | 0.80930 |
| 2016 | 0.28870 | 10.75 | 61.15 | 0.41010 | 0.36875 | 0.77885 |
| 2017 | 0.27930 | 16.45 | 63.55 | 0.43695 | 0.35155 | 0.78850 |
| 2018 | 0.29030 | 17.80 | 73.95 | 0.46415 | 0.36900 | 0.83315 |
| 2019 | 0.28540 | 18.20 | 70.85 | 0.45620 | 0.36730 | 0.82350 |
| 2020 | 0.28205 | 11.70 | 55.45 | 0.42960 | 0.36820 | 0.79780 |
| 2021 | 0.28070 | 14.00 | 60.00 | 0.43280 | 0.36240 | 0.79520 |
| 2022 | 0.26795 | 11.40 | 51.10 | 0.40380 | 0.34435 | 0.74815 |
パリーグもセリーグと同様2018年の打撃成績が非常に良いです。
この共通点から、2018年は飛びやすいボールが使われているのかも?という推測はあながち大外れではない可能性が出てきました。
また、パリーグはセリーグよりも2020年以降の打撃成績下降が見られます。
これはもしかすると、新型コロナウイルスの影響が少なからずあるかも知れません。
セリーグも2020年以降打撃成績はあまり良くなかったのですが、過去と比較してそれほど悪いわけではなかったため、新型コロナウイルスと打撃成績の関係はあまりないのかなと考えていましたが、どうやら少なからず影響はありそうです。
セリーグパリーグ比較
では続いて、セリーグとパリーグの打撃傾向を比べてみましょう。
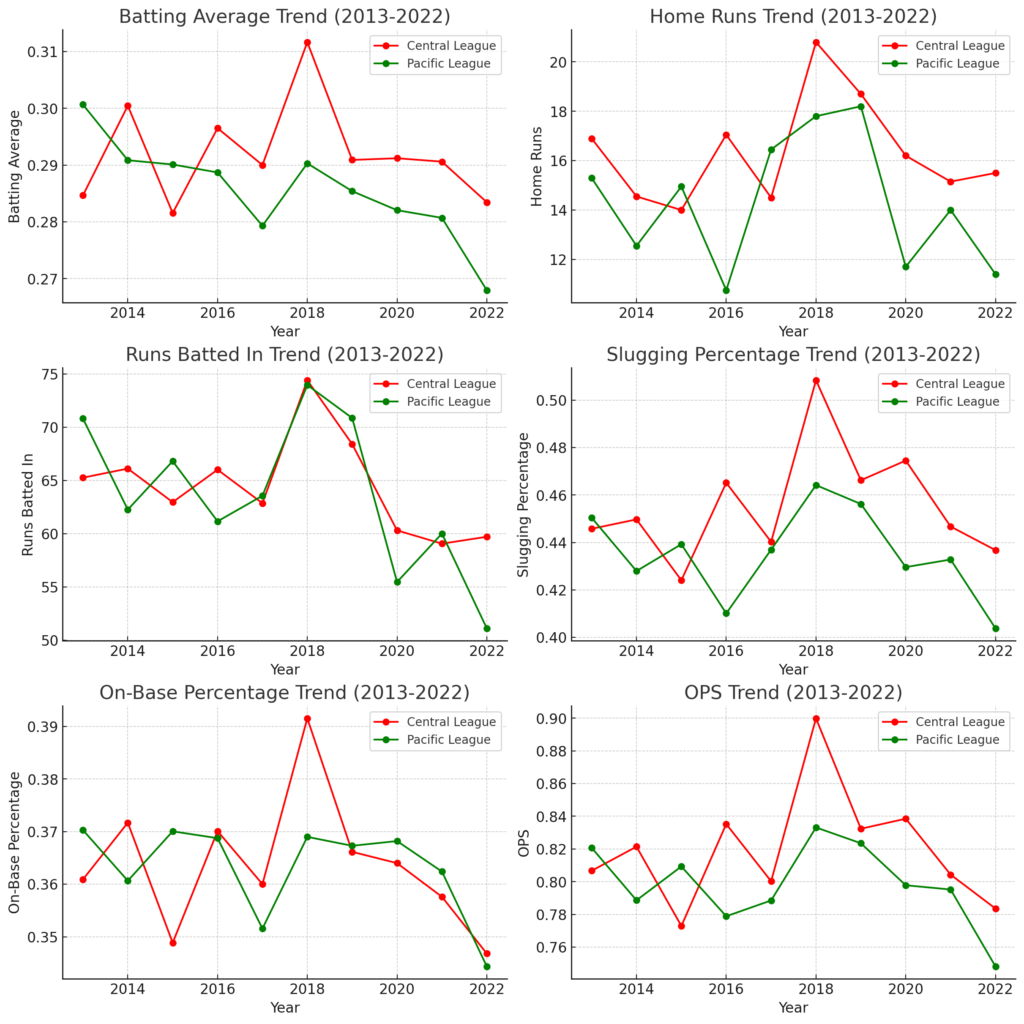
赤色がセリーグ、緑色がパリーグになります。
こうして比較してみると、上位20選手の打撃成績だけを見ると、セリーグとパリーグにそれほど違いがあるように見えません。むしろ直近10年ではセリーグの方が成績が良いように見えます。特に長打率やOPSといった成績はセリーグがほとんどの年でパリーグを上回っています。
この結果から、個人のバッターだけを見るとセリーグパリーグに大きな差はない、むしろセリーグの方がいい選手が多いことがわかりました。
では、パ高セ低となるのは、どのような要因になるのでしょうか?
今回の結果から、例えば以下のような要因があるのかも知れません。
・パリーグの方が良い投手が集まりやすい傾向がある。
・パリーグは一部のチームにいいバッターが集まっており、セリーグは散らばっている。
次回のブログでは、この1つ目の”パリーグの方が良い投手が集まりやすい傾向がある。”という観点からセリーグとパリーグの比較をしようと思います。
最後に:Chat gptで分析をしてみての感想
ここまでは、分析対象(セリーグパリーグの打撃成績の傾向)に関する感想や示唆をご紹介しましたが、最後に実際にChat gptでデータ分析をしてみて感じたことをご紹介して締めくくりたいと思います。
実際にChat gptでデータ分析をしてみて感じたことは大きく2つあります。
1つ目は、多くの人にとってデータ分析がより身近になるだろうという点です。
そしてもう1つは、インプットとなるデータの質がより重要になるという点です。
まず1つ目の、多くの人にとってデータ分析がより身近になるという点についてですが、
正直今回はかなり簡単なレベルの分析をしていたため、エクセルでも事足りる範囲ではありました。
しかし、Chat gptに分析する元となる資料さえ用意すれば、あとは指示をするだけでほとんど思い通りのアウトプットが出てくるため、自分で製作するよりも圧倒的に効率が良いと感じました。

こんな感じで指示するだけであとはChat gptがやってくれるので、統計学やプログラミングの知識がない方でもデータから示唆を生み出すことがより簡単になりそうです。
次にインプットとなるデータの質の重要性がより一層増すことになるだろうという点です。
この”質”はデータ値の質という点と、フォーマットの質という2点を指します。
データ値の質とは、入力される値の正確性や、標準化されているか?といった点を意味しています。
例えば、選手の打率に入力ミスがある(正確性の欠如)、パリーグとセリーグで打撃の指標が違う(標準化の欠如)などがあった瞬間、分析はあまり意味がないものになります。
今回は、NPBのホームページに載っている情報を利用したので、入力されているデータの心配は無い(はず!)と考えていますが、例えば社内のデータを分析するといった場合は上記観点を念頭におきながら分析を行う必要があります。
続いてフォーマットの質ですが、これはエクセルを分析しやすいようにあらかじめ整形する必要があるかどうかを指します。
例えば、今回の場合NPBのHPをそのままエクセルにコピペすると以下のようになってしまいます。
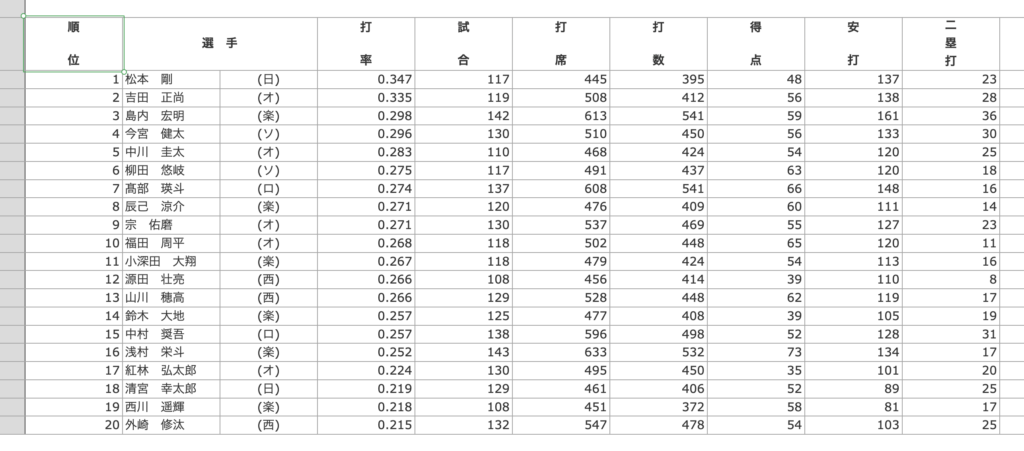
選手名とチーム名の2列に分かれているにも関わらず、メタデータは”選手”でセル結合されてしまっています。
このようなセル結合が存在すると分析がうまくいきませんでした。
これを解決するため、データの整備を手で行わないとならず、分析を行うまでの時間が少しかかってしまいました。
今回は外部のデータを利用したため仕方がないのですが、もし社内のデータを分析する場合はきちんと分析しやすいフォーマットを決め、そのフォーマットに沿って入力を行ってもらうといったことが重要になりそうです。
以上、長々と書いてしまいましたが、データ分析がより身近になり、色々な人がデータから新たな示唆や価値を生み出す未来がすぐそこまできていることに非常にワクワクしました!
次回は投手編でデータの分析してみたいと思います!それでは!!








